After several tries, I have found out that GroupNorm works suprisingly well on detection models. Just turn on the GroupNorm of FPN and I can get an improvement with a large margin. Going further, I want to replace Batchnorm of the backbone with GroupNorm and see how I can utilize this layer in other networks.
Paper: overview and comments
Criticism about BatchNorm
It does not work well on models trained with small batches. Some papers showed that BatchNorm is mainly to get the activation distribution in control to help the training convergence. Therefore, if we already have good initialization, we don’t even need to use BatchNorm.
Related works
- Local Response Normalization.
- Batch Normalization (or Spatial Batch Norm in some frameworks).
- Layer Normalization.
- Weight Normalization.
- Batch Renormalization.
- Synchronized Batchnorm: [Bag of Freebies for Training Object Detection Neural Networks] use this technique instead of GroupNorm for Yolov3, I wonder why.
- Instance Normalization.
Group-wise computation
- ResNext.
- MobileNet. Note to self: after several weeks working on detection, we found out that MobileNet does not work well for detection. One paper supports this observation [Light-Weight RetinaNet for Object Detection] . Their observation is also consistent with my experiment results, especially about the low confidence scores of the model.
- Xception.
Normalization Revisiting and Formulation
The authors did a nice job which is to unify the formula of popular normalization techniques. Take a look the figure, in some extends, we can say that GroupNorm is a variant of LayerNorm and Instance Norm.
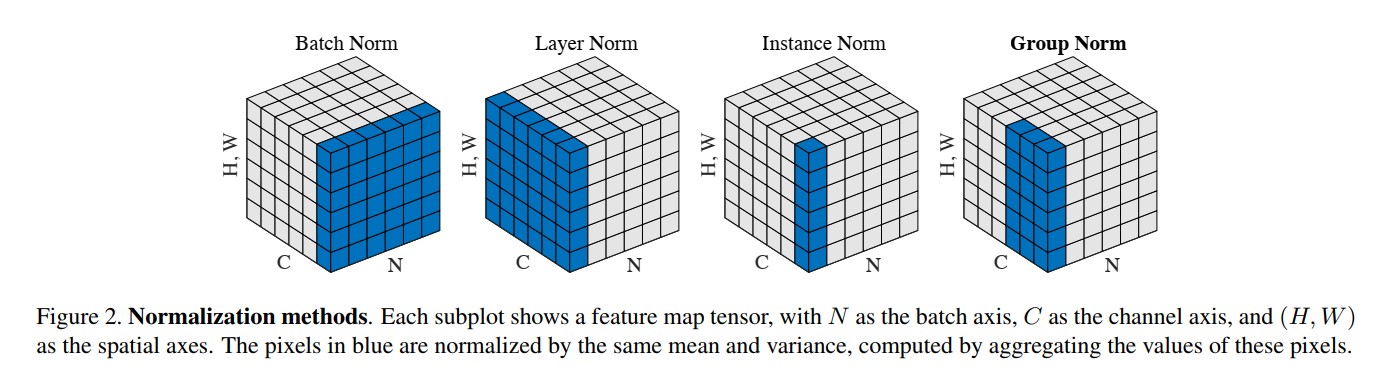
Normalization Methods
Interestingly, Layer Norm looks oddly like the pooling method in Triangulation Embedding, or other higher-level features. Based on the figure, we also figure out why Batch Norm is not effective on small batch size, namely N is small and there are not enough sample to compute the good approximation for two moments (mean and variance). So how do other methods try to overcome that problem? They try to compute the statistics on the channel itself. Most of the common CNN models use 64, 128 or 256 channels in the conv layer, hence we have relatively enough values in order to compensate the lack of samples in each batch.
Regarding the computation, the family of normalization layers are composed of two steps:
- Compute the statistics and normalize the input:
$$ \hat{x_i} = \frac{1}{\sigma_i} (x_i - \mu_i) $$
where $\mu_i$ and $\sigma_i$ are computed for a subset $S_i$ of feature maps from a batch of input. The art of creating a new normalization layer is how to design a new subset which is able to overcome some shortcomings of previous methods.
- For each channel, learn a linear transformation to compensate for the possible lost of representational ability:
$$ y_i = \gamma \hat{x_i} + \beta $$
where $\gamma$ and $\beta$ are trainable scale and shift.
Implementation
The paper also mentioned the Tensorflow implementation, I don’t want to talk about it much. However, the C++ implementation from caffe2 is worth reading. Why? Since it computes 2 moments in the inference time, hence I thought there is no way to integrate the layer into the penultimate Conv Layer, which is kind of disappointed since I want to optimize the inference model on mobile.
Interestingly, I’ve also found that there are different implementations for BatchNorm and there is no agreement across all popular deep learning frameworks about whether or not Bessel’s corrections are applied.
Surprisingly enough, by using running standard deviations, we can avoid some serious numerical errors and get better approximation compared to the textbook formula of standard deviation. Some discussions are the problem and how to compute std can be found in The Art of Computer Programming, Volume 2, Section 4.2.2 or wiki page of calculating variance.
Experiments
| Setting | Label Recall | Label Precision |
|---|---|---|
| Dataset 1 (AffineChannel) | 0.2464 | 0.3310 |
| Dataset 1 (GroupNorm) | 0.2676 | 0.3615 |
| Dataset 2 (AffineChannel) | 0.2492 | 0.3400 |
| Dataset 2 (GroupNorm) | 0.2620 | 0.3761 |
From my own experiments whose model essentially are RetinaNet from Detectron library, GroupNorm indeed helps to improve the performance of detection models (+8% on recall and precision, of course, after setting the corresponding thresholds) on two COCOesque datasets. However, adapting GroupNorm to mobile frameworks may be difficult, some don’t support this layer and we have to write our own CPU/CUDA code. Another workaround is to stick to BatchNorm, use smaller image size to train and increase the batch size. AffineChannel is another choice. It is relatively good and easily to merge into the conv layer in order to save the memory.
Nonetheless, GroupNorm is only used in the FPN layers in all settings. I wonder what happens if I replace all AffineChannel or Spatial BatchNorm by GroupNorm, even on the backbone. I will put the results soon (If I have time to do such experiments).
In conclusion, GroupNorm is simple yet effective normalization method to use in case you have to train models with small batch size.