In this post, I will discuss two papers that try to handle the partially annotated datasets. Let talk a bit about why we care about missing annotations in detection. Firstly, labeling box is difficult and tedious. Increasing the size of taxonomy also exponentially increase the difficulty of the task. Secondly, Suppose that originally we have a training dataset with 20 categories, later, we want to add 10 more new categories into the model. The question is: do we need to reannotate the training dataset? Or do we have any techniques that automatically solve the problem? Recently, we have the Open Images Dataset with a huge number of images and annotations, hence, the community also becomes interested in this problem. I found two papers that are interesting:
- Wu, Zhe, et al. “Soft sampling for robust object detection.” arXiv preprint arXiv:1806.06986 (2018).
- Niitani, Yusuke, et al. “Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects.” arXiv preprint arXiv:1811.10862 (2018).
In the first paper, the authors try to study the robustness of the object detection system under the presence of mission annotations. I have done this one before with COCO-like datasets. However, the authors have a systematic way to conduct experiments than me. Their conclusion is also interesting:
we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset.
The thing is: the conclusion is drawn when you set the detection threshold at 0. It is not possible for any real object detections. You have to set higher thresholds in order to maintain certain precision/recall. I believe that any commercial object detection systems do that. For that reason, if we look at the result at a threshold larger than 0.4, we can observe a significant drop in term of mAP, which makes sense. That being said, the authors also mentioned in section 4 that “it is important for practitioners to tune the detection threshold per class when using detectors trained on missing labels”.
The little game is the second figure of the paper in which they show the
performance changes on trainval and test set of VOC2007 with different
detection thresholds.
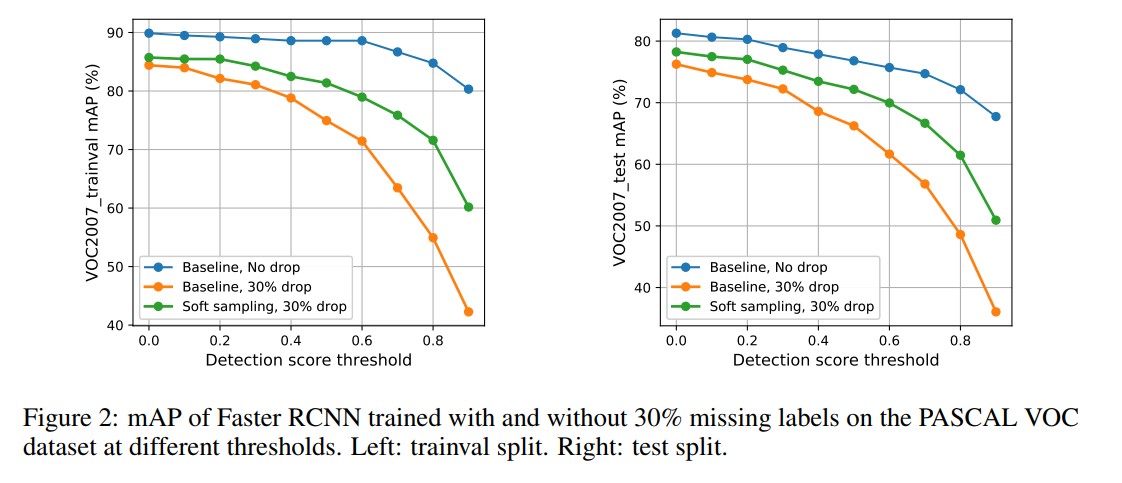
Performance changes on various detection thresholds
One thing worth noting in the experiment setting is that they drop groundtruth boxes across all classes, which is quite different compared to the scenario in which we add more class into the trained model. While the former setting does not change any taxonomy, the latter revamps the whole label information.
Now, let move on to the proposed method. Firstly, they suggest using hard-mining example sampling to tackle the missing annotation problem. The reason is that by mining hard examples, we can avoid randomly sampling the missing annotation regions. Then, they propose a fancy function that weights the gradient based on the IoU overlapping value. To this point, you can see that the proposed method is just another form of Balance IoU Sampler.
So, there is nothing surprising here.
The authors also propose another approach (otherwise, the paper is just too short to appear in any conferences). This time they want to weight the gradient of ROIs that are not positives or hard negatives. The weight function is akin to the aforementioned weight function. So basically, they believe their model, hoping that it relatively predict the correct objects. If the considering ROIs (of course, neither positive nor hard negative ROIs) has a high score, they consider it as a positive ROI and enforce the gradient, otherwise just subdue that ROI. They also mentioned that the trained model is quite weak, hence this approach does not work well. The experiment results clearly support the observation.
Now, let talk about the second paper. The proposed method is named as pseudo label-guided. Their observation is that if an object presents in the image, some parts of the object should be included as well. Say you have a car in a photo, it probably also has tires in that photo as well. In other words, this kind of approach is only suitable for hierarchical taxonomies.
The proposed method is composed of two components:
-
part-aware sampling: they simply ignore the classification loss of part categories when an instance of them is inside an instance of their subject categories.
-
pseudo labels: to exclude regions that are likely not to be annotated.
So, basically, they want to ignore those regions they think are missed annotated.
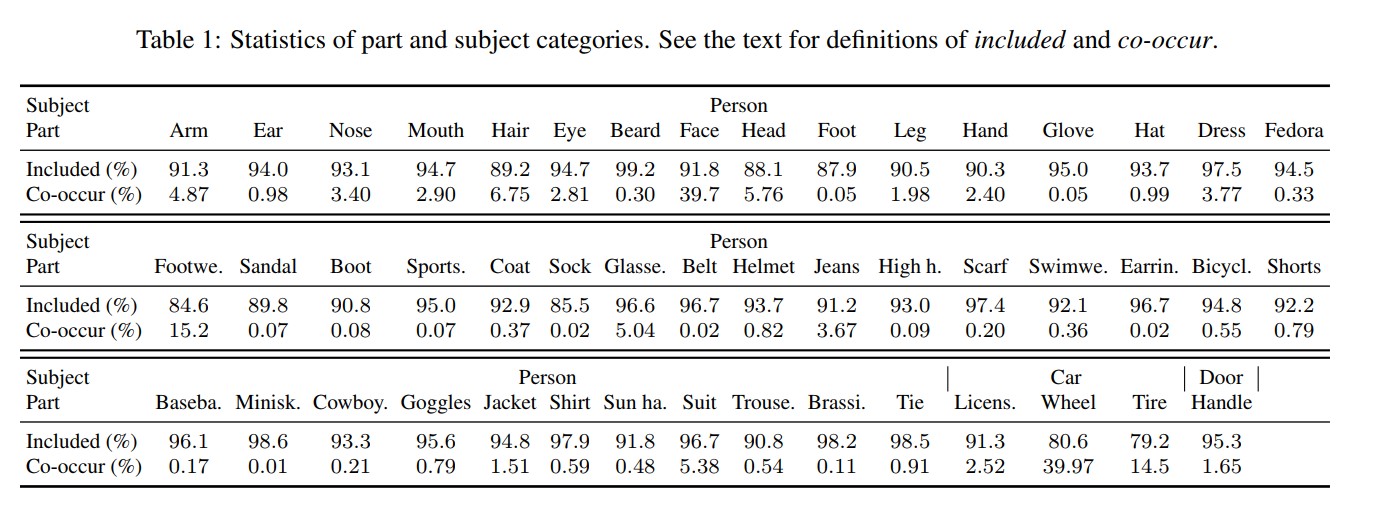
Table 1. in the paper is interesting. There are two notions here:
- Included: the ratio between a set of part component and subject category in the same instance and total bounding boxes of the part component.
- Co-occur: the ratio between images obtains both part and subject categories and total images having subject categories.
The number suggests that missing annotation are a severe problem in the Open Images Dataset.
Even though they summarized two algorithms in the paper, it is worth translating them to English:
-
Part-ware sampling: For each RoI proposal (Line 1), check if the associated groundtruth (Line 3) contains part categories (Line 4). If it does, ignore those labels (Line 6) that are not verified (Line 5).
-
Pseudo label-guided sampling: For each output from a trained model (Line 2), remove those whose score is smaller than the threshold or its label is in the verified set (Line 3), otherwise remove it if it very close to any groundtruth (Line 6). After that, for each RoI proposal (Line 8), add those box from the filtered output to the ignored groups (Line 11) if its IoU with the RoI is high enough (Line 10).
Experiments
Nothing special here, they just show off their experiment. However, I will implement soft sampling and pseudo label-guided sampling in the next couple of weeks. Let see if these methods can actually help my work or not.